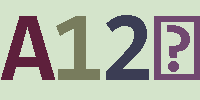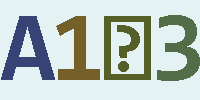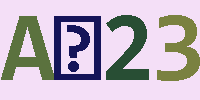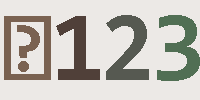实践一下使用aspose.ocr来识别验证码
aspose.ocradmin 发布于:2024-12-10 13:39:56
阅读:loading
OCR识别我一直认为是门好东西,最近几天aspose.ocr组件升级了24.11.1的版本,经过尝试发现这个版本较之于前面的版本对中文的支持不可谓不好,实属非常棒,所以在使用它编写了对车牌号的识别后,又趁热打铁来实践一下aspose.ocr的身份证识别,识别的结果仍然是非常好。
本篇文章对于aspose.ocr图片识别验证码的示例实践,笃定你对aspose.ocr已经有了一定的了解,或者也看到过本站此系列的其他相关文章,所以直接上示例素材、示例代码、示例结果,详细如下。

(1)总共照了13张验证码素材,大概4种风格的,第一行来源于某摇号网站的登录验证码,其它验证码图片也均来自于网络;
(2)上图中的布局展示,上方是源验证码图片,下方是识别结果,标绿色的文本表示识别正确,标记红色的表示未成功(不能全部成功)识别;
(3)上图中的验证码图片,可以看到对于有旋转角度的文本识别的要差一点,对于有较多颜色点的来说,也同样难以识别;
public void test() throws Exception {
//Resources.FetchAll();//加载语言包
//输出本地的语言包
final List<String> list = Resources.ListLocal();
System.out.println("list = " + list);
AsposeOCR ocr = new AsposeOCR();
RecognitionSettings settings = new RecognitionSettings();
settings.setLanguage(Language.Eng);
settings.setAllowedCharacters(CharactersAllowedType.ALL);
settings.setLinesFiltration(true);
settings.setAutomaticColorInversion(true);
/*settings.setUpscaleSmallFont(true);*///该参数为false可以识别codeddd.jpg文件结果
settings.setThreadsCount(5);
OcrInput input = new OcrInput(InputType.SingleImage);
input.add(URLDecoder.decode(getClass().getResource("/code/code111.jpg").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/code222.jpg").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/code333.jpg").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/code444.jpg").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/code555.jpg").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/code666.jpg").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/code777.gif").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/code888.gif").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/code999.gif").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/codeaaa.gif").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/codebbb.gif").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/codeccc.gif").getPath() , StandardCharsets.UTF_8.name()));
input.add(URLDecoder.decode(getClass().getResource("/code/codeddd.jpg").getPath() , StandardCharsets.UTF_8.name()));
ocr.CalculateSkew(input);
final ArrayList<RecognitionResult> results = ocr.Recognize(input, settings);
for (int i = 0; i < results.size(); i++) {
RecognitionResult result = results.get(i);
System.out.println((i + 1) + "---" + result.recognitionAreasText + "---" + result.recognitionText);
}
}list = [aspose-ocr-advanced-recognition-v1, aspose-ocr-chinese-v1, aspose-ocr-chinese-v2, aspose-ocr-cyrillic-v1]
1---[Mk5E]---Mk5E
2---[8E8t]---8E8t
3---[LExh]---LExh
4---[dA6t]---dA6t
5---[]---
6---[]---
7---[0S]---0S
8---[9XRB]---9XRB
9---[EF2]---EF2
10---[5D8]---5D8
11---[SeS]---SeS
12---[2SE]---2SE
13---[2 Kp 4]---2 Kp 4包含13个验证码图片《![]() code.zip》的素材,如果你也掌握了其它相关ocr识别的实现,不妨试下这些图片的识别结果。
code.zip》的素材,如果你也掌握了其它相关ocr识别的实现,不妨试下这些图片的识别结果。
点赞





发表评论
当前回复:作者